小喵的唠叨话:小喵最近在做人脸识别的工作,打算将汤晓鸥前辈的DeepID,DeepID2等算法进行实验和复现。DeepID的方法最简单,而DeepID2的实现却略微复杂,并且互联网上也没有比较好的资源。因此小喵在试验之后,确定了实验结果的正确性之后,才准备写这篇博客,分享给热爱Deep Learning的小伙伴们。
能够看到这篇博客的小伙伴们,相信已经对Deep Learning有了比较深入的了解。因此,小喵对亲作了如下的假定:
- 了解Deep Learning的基本知识
- 目前在做人脸识别的相关工作
- 仔细阅读过DeepID和DeepID2的论文
- 使用Caffe作为训练框架
- 即使不满足上述4个条件,也会持之以恒的学习
如果亲发现对上述的条件都不满足的话,那么这篇博文可能内容还是略显枯涩乏味,你可以从了解Caffe开始,慢慢学习。
相关资源:
- DeepID:http://mmlab.ie.cuhk.edu.hk/pdf/YiSun_CVPR14.pdf
- DeepID2:http://papers.nips.cc/paper/5416-analog-memories-in-a-balanced-rate-based-network-of-e-i-neurons
- Caffe:http://caffe.berkeleyvision.org/
由于篇幅较大,这里会分成几个部分,依次讲解。
一、设计我们独特的Data层
在DeepID2中,有两种监督信号。一是Identity signal,这和DeepID中的实现方法一样,用给定label的人脸数据,进行分类的训练,这里使用 softmax_with_loss 层来实现(softmax + cross-entropy loss)。这里不再介绍。另一种就是verification signal,也就是人脸比对的监督。这里要求,输入的数据时成对存在,每一对都有一个公共的label,是否是同一个类别。如果是同一个identity,则要求他们的特征更接近,如果是不同的identity,则要求他们的特征尽可能远离。
不论最终怎么实现,我们的第一步是确定的,构造合适的数据。
使用Caffe训练的时候,第一步是打Batch,将训练数据写入LMDB或者LevelDB数据库中,训练的时候Caffe会从数据库中读取图片,因此一个简单的实现方法就是构造许多的pair,然后打Batch的时候就能保证每对图片都是相连的,然后在训练的时候做一些小Trick就可以实现。
但是就如上面所说,打Batch的同时,图片的顺序就已经是确定的了,因此网络输入的图片pair也是固定的,这样似乎就缺乏了一些灵活性。
那么如何动态的构造我们的训练数据呢?
设计我们独特的data层。
这里为了方便,使用Python来拓展Caffe的功能。Python是一门简洁的语言,非常适合做这种工作。不过Caffe中如果使用了Python的层,那么就不能使用多GPU了,这点需要注意(希望以后能增加这个支持)。
1)让你的Caffe支持Python拓展
在Caffe根目录的Makefile.config中,有这么一句话。
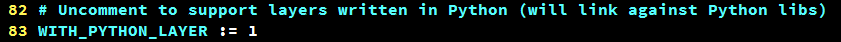
我们需要使用Python层,因此需要取消这个注释。之后Make一下你的Caffe和pycaffe。这样Caffe就支持Python层了。
2)编写data层
基于Python的data层的编写,Caffe是给了一个简单的例子的,在/caffe_home/examples/pycaffe/layers/中。我们简单的照着这个例子来写。
首先,我们定义自己需要的参数。这里,我们需要:
- batch_size: batch的大小,没什么好解释的,要求这个数是大于0的偶数
- mean_file:图像的均值文件的路径
- scale:图像减均值后变换的尺度
- image_root_dir:训练数据的根目录
- source:训练数据的list路径
- crop_size:图像crop的大小
- ratio:正样本所占的比例(0~1)
caffe在train.prototxt中定义网络结构的时候,可以传入这些参数。我们目前只需要知道,这些参数一定可以获取到,就可以了。另外,source表示训练数据的list的文件地址,这里用到的训练数据的格式和Caffe打batch的数据一样。
file_path1 label1
file_path2 label2这样的格式。
Data层的具体实现,首先需要继承caffe.Layer这个类,之后实现setup, forward, backward和reshape,不过data层并不需要backward和reshape。setup主要是为了初始化各种参数,并且设置top的大小。对于Data层来说,forward则是生成数据和label。
闲话少说,代码来见。
#-*- encoding: utf-8 -*-
import sys
import caffe
import numpy as np
import os
import os.path as osp
import random
import cv2
class id2_data_layer(caffe.Layer):
"""
这个python的data layer用于动态的构造训练deepID2的数据
每次forward会产生多对数据,每对数据可能是相同的label或者不同的label
"""
def setup(self, bottom, top):
self.top_names = ['data', 'label']
# 读取输入的参数
params = eval(self.param_str)
print "init data layer"
print params
self.batch_size = params['batch_size'] # batch_size
self.ratio = float(params['ratio'])
self.scale = float(params['scale'])
assert self.batch_size > 0 and self.batch_size % 2 == 0, "batch size must be 2X"
assert self.ratio > 0 and self.ratio < 1, "ratio must be in (0, 1)"
self.image_root_dir = params['image_root_dir']
self.mean_file = params['mean_file']
self.source = params['source']
self.crop_size = params['crop_size']
top[0].reshape(self.batch_size, 3, params['crop_size'], params['crop_size'])
top[1].reshape(self.batch_size, 1)
self.batch_loader = BatchLoader(self.image_root_dir, self.mean_file, self.scale, self.source, self.batch_size, self.ratio)
def forward(self, bottom, top):
blob, label_list = self.batch_loader.get_mini_batch()
top[0].data[...] = blob
top[1].data[...] = label_list
def backward(self, bottom, top):
pass
def reshape(self, bottom, top):
pass
class BatchLoader(object):
def __init__(self, root_dir, mean_file, scale, image_list_path, batch_size, ratio):
print "init batch loader"
self.batch_size = batch_size
self.ratio = ratio # true pair / false pair
self.image2label = {} # key:image_name value:label
self.label2images = {} # key:label value: image_name array
self.images = [] # store all image_name
self.mean = np.load(mean_file)
self.scale = scale
self.root_dir = root_dir
with open(image_list_path) as fp:
for line in fp:
data = line.strip().split()
image_name = data[0]
label = data[-1]
self.images.append(image_name)
self.image2label[image_name] = label
if label not in self.label2images:
self.label2images[label] = []
self.label2images[label].append(image_name)
self.labels = self.label2images.keys()
self.label_num = len(self.labels)
self.image_num = len(self.image2label)
print "init batch loader over"
def get_mini_batch(self):
image_list, label_list = self._get_batch(self.batch_size / 2)
cv_image_list = map(lambda image_name: (self.scale * (cv2.imread(os.path.join(self.root_dir, image_name)).astype(np.float32, copy=False).transpose((2, 0, 1)) - self.mean)), image_list)
blob = np.require(cv_image_list)
label_blob = np.require(label_list, dtype=np.float32).reshape((self.batch_size, 1))
return blob, label_blob
def _get_batch(self, pair_num):
image_list = []
label_list = []
for pair_idx in xrange(pair_num):
if random.random() < self.ratio: # true pair
while True:
label_idx = random.randint(0, self.label_num - 1)
label = self.labels[label_idx]
if len(self.label2images[label]) > 5:
break
first_idx = random.randint(0, len(self.label2images[label]) - 1)
second_id = random.randint(0, len(self.label2images[label]) - 2)
if second_id >= first_idx:
second_id += 1
image_list.append(self.label2images[label][first_idx])
image_list.append(self.label2images[label][second_id])
label_list.append(int(label))
label_list.append(int(label))
else: # false pair
for i in xrange(2):
image_id = random.randint(0, self.image_num - 1)
image_name = self.images[image_id]
label = self.image2label[image_name]
image_list.append(image_name)
label_list.append(int(label))
return image_list, label_list上述的代码可以根据给定的list,batch size,ratio等参数生成符合要求的data和label。这里还有一些问题需要注意:
- 对输入的参数没有检验。
- 没有对读取图像等操作做异常处理。因此如果很不幸地读到的图片路径不合法,那么程序突然死掉都是有可能的。。。小喵的数据都是可以读的,所以木有问题。
- 在选取正负样本对的时候,对于正样本对,只有样本对应的label中的图片数大于5的时候,才选正样本(小喵的训练数据每个人都有至少几十张图片,所以木有出现问题),如果样本比较少的话,可以更改这个数(特别是有测试集的时候,测试集通常数目都很少,小喵训练的时候都是不用测试集的,因为会死循环。。。)。对于选取负样本对的时候,只是随便选了两张图片,而并没有真的保证这一对是不同label,这里考虑到训练数据是比较多的,所以不大可能选中同一个label的样本,因此可以近似代替负样本对。
- 这里有个减均值的操作,这个均值文件是经过特殊转换求出的numpy的数组。Caffe生成的均值文件是不能直接用的,但是可以通过仿照Caffe中Classifier中的写法来代替(caffe.io.Transformer工具)。另外这里的图片数据和均值文件是一样大小的,但实际上可能并不一定相等。如果需要对输入图片做各种随机化的操作,还需要自己修改代码。
至此,我们就完成了一个简单的Data层了。
那么怎么调用自己的data层呢?
这里有一个十分简单的写法。在我们用来训练的prototxt中,将Data层的定义改成如下的方式:
layer {
name: "data"
type: "Python"
top: "data"
top: "label"
include {
phase: TRAIN
}
python_param {
module: "id2_data_layer"
layer: "id2_data_layer"
param_str: "{'crop_size' : 128, 'batch_size' : 96, 'mean_file': '/your/data/root/mean.npy', 'scale': 0.0078125, 'source': '/path/to/your/train_list', 'image_root_dir': '/path/to/your/image_root/'}" }
}python_param中的这三个参数需要注意:
module:模块名,我们先前编写的data层,本身就是一个文件,也就是一个模块,因此模块名就是文件名。
layer:层的名字,我们在文件中定义的类的名字。这里比较巧合,module和layer的名字相同。
param_str:所有的需要传给data层的参数都通过这个参数来传递。这里简单的使用了Python字典的格式的字符串,在data层中使用eval来执行(o(╯□╰)o 这其实并不是一个好习惯),从而获取参数,当然也可以使用别的方式来传递,比如json或者xml等。
最后,你在训练的时候可能会报错,说找不到你刚刚的层,或者找不到caffe,只需要把这个层的代码所在的文件夹的路径加入到PYTHONPATH中即可。
export PYTHONPATH=PYTHONPATH:/path/to/your/layer/:/path/to/caffe/python这样就完成了我们的Data层的编写,是不是非常简单?
重要更新:
1,小喵最近发现直接在image_data_layer.cpp中进行修改,可以更好的实现这个目标,而且支持多GPU。
2,训练的数据可以只用正样本对,因为identity signal已经十分强调不同identity的feature之间的距离,因此verification signal只需要强调相同的identity的feature相近就好。
3,小喵新的训练数据,构造pair的方式也做了修改。每次使用所有的数据构造pair,然后用来训练,每个epoch后都重新生成一次list。这样可以保证identity signal能够每次训练所有的图片,而verification signal也能每次训练不同的样本对。
转载请注明出处~